Hosting in S3 with CloudFront
In the last post, I outlined my process to block public S3 buckets at the service level, ensuring that none of the buckets across my accounts would be exposed unintentionally. Once I was comfortable with the solution, I decided that it would be nice to finally set up a blog hosted in S3. My requirements were the following:
- Maintain the security posture of the hosting bucket
- Maintain access logs, and be able to report on them
- Content to only be delivered via TLS
- Ensure management of the certificate lifecycle was straight forward
At this point, I was still evaluating a couple of static Content Management Solutions (CMS), one of which was to abandon this entire exercise and adopt Github Pages. I knew if I did, I would be able to deliver content faster, but I wouldn’t learn about the underlying infrastructure. Once I committed to hosting in S3, the first step was to figure out how I would handle the first requirement.
In AWS, there are an endless number of ways to build a solution. For this use case, cost, and ease of deployment were my drivers, which narrowed the scope to one of two:
- Front the S3 bucket with nginx in ec2 1
- Use CloudFront
Option 2 would help me learn about the nuances of the content delivery network (CDN) designed by AWS, and give me the opportunity to stretch my CloudFormation skills. The intent being that if I could automate the roll out of this solution I could use it for other projects that I want to start that require the same architecture.
The first step was to figure out how to provide access to CloudFront to the target S3 bucket without having to set any of the S3 Block Public Access policies to false. I spent quite a few hours reading through both the CloudFront, and the S3 developer guides, finally coming across documentation on giving a CloudFront Origin Identity access to the S3 bucket using either a bucket access control list (ACL) or bucket policy. In my opinion, bucket policies are significantly easier to deal with because they use the same syntax as IAM policies. I left the bucket ACL alone, and added the following bucket policy:
SiteBucketPolicy:
Type: AWS::S3::BucketPolicy
Properties:
Bucket: !Ref SiteBucket
PolicyDocument:
Statement:
-
Sid: Grant a CloudFront Origin Identity access to support private content
Effect: Allow
Principal:
CanonicalUser: !GetAtt CDNIdentity.S3CanonicalUserId
Action: s3:GetObject
Resource: !Sub
- '${SiteBucketARN}/*'
- { SiteBucketARN: !GetAtt SiteBucket.Arn }The tricky piece of this was figuring out how to conjure up the value to fill in for the Principal. Back to the CloudFront Origin Identity documentation, and the CloudFormation reference for CloudFront to give me my answer.
CDNIdentity:
Type: AWS::CloudFront::CloudFrontOriginAccessIdentity
Properties:
CloudFrontOriginAccessIdentityConfig:
Comment: !Sub 'OAI for ${SiteDomainName}'This was by far the most difficult piece, and I knew that once I had figured it out, the rest of it would be straight forward… and it was!
Setting up the certificate for use by CloudFront was easy, as my requirements were that one, I could issue a certificate with a wildcard subject name, and two, that the validation process could be completed via e-mail. The validation requirement was only so that I didn’t have to depend on Time To Live (TTL) values on Domain Name Servers (DNS) while the CloudFormation was running. The risk of the stack timing out before a new DNS record could be validated was high. In comparison, e-mail validation was effectively real-time. The resource definition for the certificate is four lines:
SiteCertificate:
Type: AWS::CertificateManager::Certificate
Properties:
DomainName: !Sub '*.${SiteDomainName}'
ValidationMethod: EMAILWith all the dependencies for the CloudFront distribution in place, I could build the resource definition for it. I will note that the number of options available for configuring the resource were many. I used my initial requirements to dictate the configuration options I chose, narrowing again, by ease of use (for me, and the viewer), as well as cost. This is the final resource configuration I went to production with:
SiteCDN:
Type: AWS::CloudFront::Distribution
Properties:
DistributionConfig:
Aliases:
- !Sub 'www.${SiteDomainName}'
CustomErrorResponses:
-
ErrorCode: 403
ResponseCode: 404
ResponsePagePath: /404.html
DefaultCacheBehavior:
Compress: true
ForwardedValues:
QueryString: false
TargetOriginId: !Ref SiteDomainName
ViewerProtocolPolicy: redirect-to-https
DefaultRootObject: index.html
Enabled: true
Logging:
Bucket: !GetAtt LogBucket.DomainName
IncludeCookies: false
Origins:
-
DomainName: !GetAtt SiteBucket.DomainName
Id: !Ref SiteDomainName
S3OriginConfig:
OriginAccessIdentity: !Sub 'origin-access-identity/cloudfront/${CDNIdentity}'
PriceClass: PriceClass_100
ViewerCertificate:
AcmCertificateArn: !Ref SiteCertificate
MinimumProtocolVersion: TLSv1.1_2016
SslSupportMethod: sni-only
DependsOn: SiteCertificateThe PriceClass dictates where the CDN lives globally, and since there’s a significant cost difference, I chose the class where I expect most of the traffic to come from.
The entire CloudFormation template can be found in GitHub here.
Ultimately, I met my requirements, and I learned a metric ton about CloudFront. The one caveat (that I have yet to raise with the S3 team), is that with a CloudFront distribution exposing the contents of the S3 bucket, the S3 service still thinks that the bucket, and its objects are not public…
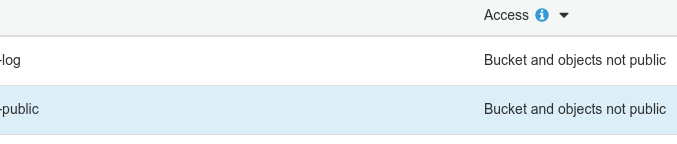
-
While I occassionally miss the days of configuring n-tier infrastructure for sites, I’m getting too old for that shit. ↩
Tweet to @kriation