Goodbye Google Analytics
Late last year, a blogger that I follow posted their journey of building their own site analytics as a replacement for Google Analytics (GA). In addition, Google announced deprecation of Universal Analytics. These two events triggered my desire to roll this site off of GA. Over the past couple of weeks, I built my own analytics “solution” using Azure Data Factory and Data Explorer. In this post, I’ll describe the process of ingesting CloudFront log data from S3 to Data Explorer using Data Factory.
If you made it to this second paragraph, I’m sure you’re thinking to yourself, “Armen, since you’re running this site in AWS, why not use Amazon Redshift or Athena to make your life easy?” You’re absolutely right in that it would be easier, especially given that there are documented solutions for both: S3 to RedShift and CloudFront to Athena However, for those of you that know me well, you know that I often (sometimes to a fault) pick the path least traveled. In this case, especially given that the industry is continuing to drive toward public cloud as a commodity, I wanted to choose the solution that worked best for me.
For this case, especially given my experience with the Kusto Query Language (KQL) over the past couple of years, I wanted the ability to run queries easily without conjuring SQL statements like I would if I used either of the aforementioned AWS solutions. With my target destination set, I put together a rough set of steps that would get me to a point where I could query the data.
- Give Azure least privilege access to the S3 bucket where the logs are located
- Copy the logs to a useful destination in Azure where they could be indexed
- Map the data appropriately so that it can be referenced through KQL statements
- Run KQL against the data to return useful reports
In the past, I struggled to find the correct combination of permissions to read contents from an S3 bucket. I’ll admit that I spent some time trying to figure out the unique combination of GetObject and ListBucket permissions but without success so I scoured the Azure documentation, and discovered the one for the Data Factory S3 Connector, which described what I needed well enough to be able to set up a user and group with the right permission.
- PolicyName: S3ReadAccess
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action:
- s3:ListBucket
- s3:GetBucketLocation
- s3:GetObject
- s3:GetObjectVersion
Resource:
- !Sub 'arn:aws:s3:::${S3BucketName}'
- !Sub 'arn:aws:s3:::${S3BucketName}/*'Once the CloudFormation was run in the account where the bucket containing the logs was located, I had a set of credentials that I could use from Azure to access the log data. The next step was to build a landing for the data from the bucket in Azure. I spent a number of days on this problem as this was my first experience building a data pipeline into Azure and I wasn’t sure what I was getting myself into.
My first attempt was to copy the data from S3 to a Storage Account in Azure and then try to figure out how to make it accessible in Data Explorer. This was an epic failure for two reasons: the first being that I wasn’t being very cost conscious in duplicating the data from one source to another, and second is that the transfer lasted over three and a half hours because the Integration Runtime I selected was the smallest size (at least that’s what I believe to be the issue).
The second attempt was to copy the data from S3 to a Data Explorer cluster directly without the intermediate Storage Account step. This attempt was completely iterative as I tested different configuration variations each time until I figured out one that worked well for me.
The first step was to create a basic Data Explorer cluster, and then a database inside the cluster. I effectively followed the steps in the documented QuickStart.
With the database created, the next step was to create the target table in the cluster, and define a schema for the ingested data. Initially, I spent time thinking about mapping each column to an appropriate data explorer scalar type but after evaluating the columns, I noticed that most of them were strings, and went along with it except for a few exceptions. The final schema I used was the following:
"Schema": {"Name":"redacted","OrderedColumns":[
{"Name":"date","Type":"System.String","CslType":"string"},
{"Name":"time","Type":"System.String","CslType":"string"},
{"Name":"edge-location","Type":"System.String","CslType":"string"},
{"Name":"server-bytes","Type":"System.Int32","CslType":"int"},
{"Name":"client-ip","Type":"System.String","CslType":"string"},
{"Name":"client-method","Type":"System.String","CslType":"string"},
{"Name":"edge-fqdn","Type":"System.String","CslType":"string"},
{"Name":"request-uri","Type":"System.String","CslType":"string"},
{"Name":"server-status","Type":"System.Int32","CslType":"int"},
{"Name":"client-referer","Type":"System.String","CslType":"string"},
{"Name":"client-useragent","Type":"System.String","CslType":"string"},
{"Name":"request-uriquery","Type":"System.String","CslType":"string"},
{"Name":"client-cookie","Type":"System.String","CslType":"string"},
{"Name":"edge-result","Type":"System.String","CslType":"string"},
{"Name":"edge-requestid","Type":"System.String","CslType":"string"},
{"Name":"server-fqdn","Type":"System.String","CslType":"string"},
{"Name":"client-protocol","Type":"System.String","CslType":"string"},
{"Name":"client-bytes","Type":"System.String","CslType":"string"},
{"Name":"server-timetaken","Type":"System.Data.SqlTypes.SqlDecimal","CslType":"decimal"},{"Name":"client-forwardedfor","Type":"System.String","CslType":"string"},
{"Name":"client-tls","Type":"System.String","CslType":"string"},
{"Name":"client-tlscipher","Type":"System.String","CslType":"string"},
{"Name":"edge-response","Type":"System.String","CslType":"string"},
{"Name":"client-protocolversion","Type":"System.String","CslType":"string"},
{"Name":"field-encryption","Type":"System.String","CslType":"string"},
{"Name":"field-encryptionfields","Type":"System.String","CslType":"string"},
{"Name":"client-port","Type":"System.String","CslType":"string"},
{"Name":"server-timetofirstbyte","Type":"System.String","CslType":"string"},
{"Name":"edge-errordetail","Type":"System.String","CslType":"string"},
{"Name":"server-contenttype","Type":"System.String","CslType":"string"},
{"Name":"server-contentlength","Type":"System.String","CslType":"string"},
{"Name":"server-rangestart","Type":"System.String","CslType":"string"},
{"Name":"server-rangeend","Type":"System.String","CslType":"string"}]},Data Explorer has a nifty function to export the create table script. For those that are curious and desire to test out the solution, here it is:
.create table tablename (['date']: string, ['time']: string, ['edge-location']: string,
['server-bytes']: int, ['client-ip']: string, ['client-method']: string, ['edge-fqdn']: string,
['request-uri']: string, ['server-status']: int, ['client-referer']: string,
['client-useragent']: string, ['request-uriquery']: string, ['client-cookie']: string,
['edge-result']: string, ['edge-requestid']: string, ['server-fqdn']: string,
['client-protocol']: string, ['client-bytes']: string, ['server-timetaken']: decimal,
['client-forwardedfor']: string, ['client-tls']: string, ['client-tlscipher']: string,
['edge-response']: string, ['client-protocolversion']: string, ['field-encryption']: string,
['field-encryptionfields']: string, ['client-port']: string, ['server-timetofirstbyte']: string,
['edge-errordetail']: string, ['server-contenttype']: string, ['server-contentlength']: string,
['server-rangestart']: string, ['server-rangeend']: string)Each of the columns above mapped directly to the 33 fields (included the new seven that were added in late December of 2019). I figured I would add it to the table schema so that if I wanted to ingest the data from the newer logs in the future, I would be able to.
With the database and the target table created, the next step was to build a pipeline in Data Factory to copy the data from S3 directly to the database in Data Explorer. A Data Factory (ADF) pipeline requires the configuration of Linked Services for each service that you intend for the pipeline to interact with. In my case, I needed to create one for S3, and one for Data Explorer.
The configuration for the S3 Linked Service was not intuitive. In fact, I spent time trying to figure out the correct combination of parameters before I landed on a configuration that worked properly. I landed on the following configuration for my target S3 bucket:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
{
"etag": "redacted",
"id": "redacted",
"name": "s3",
"properties": {
"accessKeyId": "redacted",
"additionalProperties": null,
"annotations": [],
"authenticationType": "AccessKey",
"connectVia": null,
"description": null,
"encryptedCredential": "redacted",
"parameters": null,
"secretAccessKey": null,
"serviceUrl": "https://s3.amazonaws.com",
"sessionToken": null,
"type": "AmazonS3"
},
"resourceGroup": "redacted",
"type": "Microsoft.DataFactory/factories/linkedservices"
},
The aspect of this configuration that I spent the most time on was with the serviceUrl (line 13). I had assumed I could use the FQDN of my target bucket but because of the way the dataset is configured in ADF, there is no way to specific the root path of the bucket resulting in a data retrieval failure. For this definition, all I needed to specify was the accessKeyId, the secretAccessKey (which is then encrypted), and ensure that the serviceUrl is set to https://s3.amazonaws.com.
The next step was to create a Linked Service for the target Data Explorer instance. The authentication options for the Data Explorer Linked Service are Service Principal, System Managed, and User Managed Identity. In this case, I created an Application SP without any API permissions, generated a client secret, and passed it into the Linked Service definition.
{
"etag": "redacted",
"id": "redacted",
"name": "dataexplorer",
"properties": {
"additionalProperties": null,
"annotations": [],
"connectVia": null,
"credential": null,
"database": "primary",
"description": null,
"endpoint": "redacted",
"parameters": null,
"servicePrincipalId": "redacted",
"servicePrincipalKey": null,
"tenant": "redacted",
"type": "AzureDataExplorer"
},
"resourceGroup": "redacted",
"type": "Microsoft.DataFactory/factories/linkedservices"
} The JSON above doesn’t provide enough visual context, whereas the screenshot below is more clear.
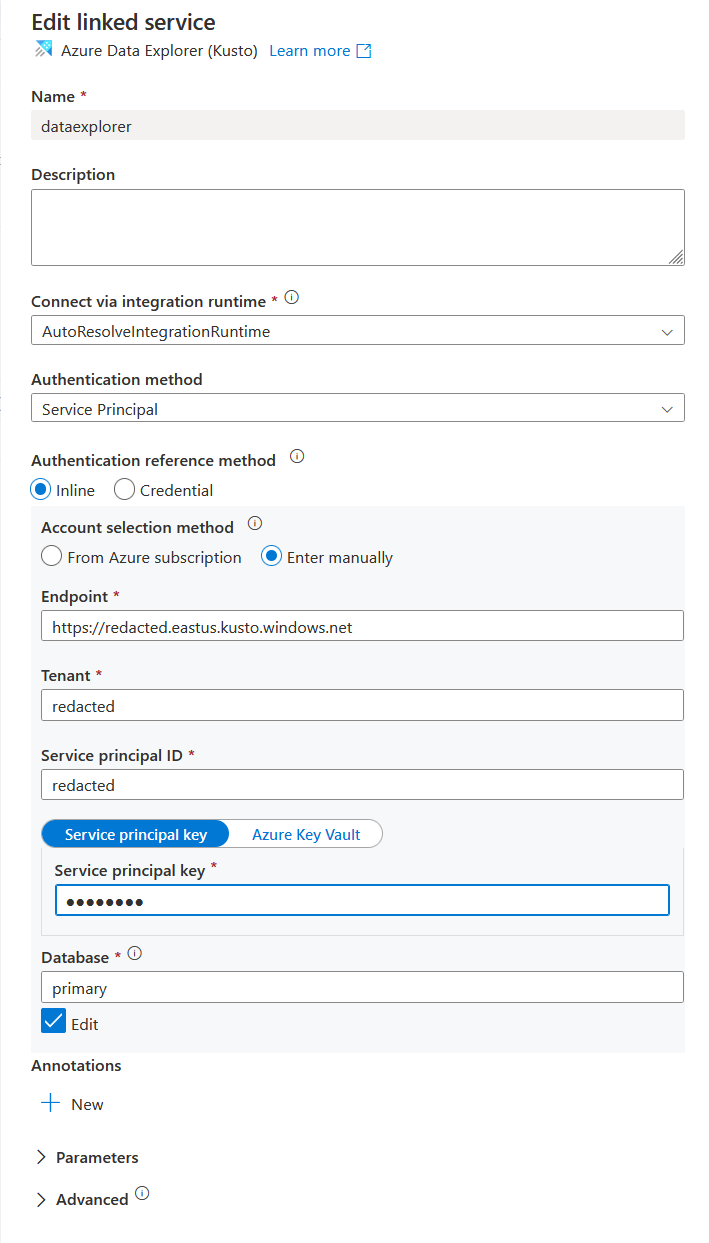
ADF also has a feature to manage credentials for a Linked Service through the Authentication reference method that includes two radio buttons: one for inline (which is what I’m using) and the other for Credential - Eventually, I’ll migrate the inline to Credential so that I can manage the lifecycle a bit better.
Once both Linked Services were created, I could move on to defining the source and destination datasets. A Dataset in ADF is an object referring to and mapping that data that will be sourced or targeted. For my use case, I had two dataset objects, one for the S3 bucket, and one for the Data Explorer table that would contain the ingested the data.
Configuring the source dataset required a bit of exploration as the logs in my bucket are several years old, and I was curious how much the data varied over time. Comparing my data to the schema for the logs provided by Amazon, I noticed that the older data didn’t match. In fact, the schema for the older log files were missing seven fields. After a quick search, I discovered an Amazon blog announcing the release of the new fields as of December 2019. I decided that it wasn’t worth for me to ingest the new fields, so I defined the schema for the source dataset to the original 26 values.
Each of the log file starts with the following two lines:
#Version: 1.0
#Fields: date time x-edge-location sc-bytes c-ip cs-method cs(Host) cs-uri-stem sc-status cs(Referer) cs(User-Agent) cs-uri-query cs(Cookie) x-edge-result-type x-edge-request-id x-host-header cs-protocol cs-bytes time-taken x-forwarded-for ssl-protocol ssl-cipher x-edge-response-result-type cs-protocol-version fle-status fle-encrypted-fieldsIdeally, I wanted to use the headers defined for each column specified in the second line, but because the line was prepend with #Fields:, it presented a problem for the schema parser (at least to my novice eyes). I decided to set the source dataset to skip the first two lines of each file, and to manually define the schema. In addition, I had to specify that the data was compressed using GZip, using the optimal compression level. The JSON definition for the source dataset is:
"name": "redacted",
"properties": {
"additionalProperties": null,
"annotations": null,
"columnDelimiter": "\t",
"compressionCodec": "gzip",
"compressionLevel": "Optimal",
"description": null,
"encodingName": null,
"escapeChar": "\\",
"firstRowAsHeader": false,
"folder": null,
"linkedServiceName": {
"parameters": null,
"referenceName": "s3",
"type": "LinkedServiceReference"
},
"location": {
"additionalProperties": null,
"bucketName": "redacted",
"fileName": null,
"folderPath": null,
"type": "AmazonS3Location",
"version": null
},
"nullValue": null,
"parameters": null,
"quoteChar": "\"",
"rowDelimiter": null,
"structure": null,
"type": "DelimitedText"
A few notes:
- The linkedServiceName includes the LinkedService that I defined earlier
- The bucketName in the location block is the simple value of the bucket without being prepended with https:// or s3://, or appended with the traditional s3 FQDN values.
- The column delimiter is specified as a tab character
- The type is defined as DelimitedText
The schema block immediately following the rowDelimiter key started as specified below:
"schema": [
{
"type": "String"
}, The String definition was defined a total of 26 times.
Once the source dataset was complete, I could move to the destination dataset. As for the source, this dataset also included a reference to the appropriate LinkedService (in this case dataexplorer).
"name": "redacted",
"properties": {
"additionalProperties": null,
"annotations": null,
"description": null,
"folder": null,
"linkedServiceName": {
"parameters": null,
"referenceName": "dataexplorer",
"type": "LinkedServiceReference"
},
"parameters": null
The last piece of this dataset block was the following definition at the end of the JSON:
"structure": null,
"table": "redacted",
"type": "AzureDataExplorerTable"Compared to the source dataset, the type for this dataset is defined as AzureDataExplorerTable. The only other parameter that’s defined in this block is the one for the target table in the database.
With the prerequisites for the pipeline created and configured, the next step was to build the pipeline and define the step inside of it to copy the data. For the first dozen times that I stepped through this process, I used the various wizards and found them to be more complicated (and frustrating) compared to defining each of the components individually. With all of the components defined, it was straight forward to build the pipeline.
A Data Factory Pipeline is simply a grouping of activities. For this case, my pipeline only has one copy activity which uses the previously defined source dataset as the input, and the destination dataset as the output. The JSON to define the source reference is as shown below:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
"source": {
"additionalColumns": null,
"additionalProperties": null,
"disableMetricsCollection": null,
"formatSettings": {
"additionalProperties": null,
"compressionProperties": null,
"skipLineCount": "2",
"type": "DelimitedTextReadSettings"
},
"maxConcurrentConnections": null,
"sourceRetryCount": null,
"sourceRetryWait": null,
"storeSettings": {
"additionalProperties": null,
"deleteFilesAfterCompletion": null,
"disableMetricsCollection": null,
"enablePartitionDiscovery": false,
"fileListPath": null,
"maxConcurrentConnections": null,
"modifiedDatetimeEnd": {
"type": "Expression",
"value": "@startOfDay(utcnow())"
},
"modifiedDatetimeStart": {
"type": "Expression",
"value": "@startOfDay(getPastTime(1, 'Day'))\n"
},
"partitionRootPath": null,
"prefix": null,
"recursive": true,
"type": "AmazonS3ReadSettings",
"wildcardFileName": "",
"wildcardFolderPath": null
},
"type": "DelimitedTextSource"
}
The most important components in this block are that I used a * for the wildcardFileName key in line 33, and that I defined a function for the start (line 23) and end times (line 27) for the file modified timestamps. This would enable me to run the pipeline once a day without changing any parameters programmatically, and ingest only the logs from the day before without risk of duplication.
The next section of the copy activity was the sink (or target) configuration. Again, as for the source, this was as simple as selected the destination dataset. The JSON for the sink is as below:
"sink": {
"additionalProperties": null,
"disableMetricsCollection": null,
"flushImmediately": null,
"ingestionMappingAsJson": null,
"ingestionMappingName": null,
"maxConcurrentConnections": null,
"sinkRetryCount": null,
"sinkRetryWait": null,
"type": "AzureDataExplorerSink",
"writeBatchSize": null,
"writeBatchTimeout": null
}As you can see, other than the type being auto-populated, the pipeline is simply going to use the destination dataset defined in the output. Once the sink was defined, the next configuration section for the copy activity was to define the mapping between the source and the destination. For this definition, as I was configuring the pipeline using the UI, I clicked on the Import Schemas button and crossed my fingers.
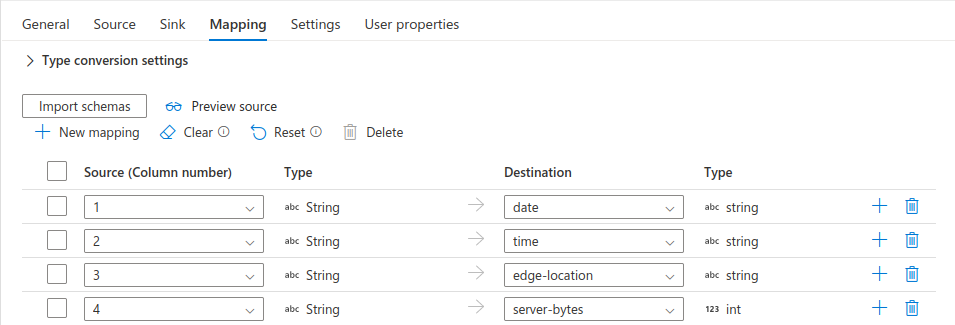
After waiting for about a minute, I was greeted with an update to the UI that presented the schema mapping exactly as I intended.
This was it! 🥳 I left the remaining settings as their default, and manually triggered the pipeline. I waited patiently (for almost three and a half hours) until the pipeline was complete…
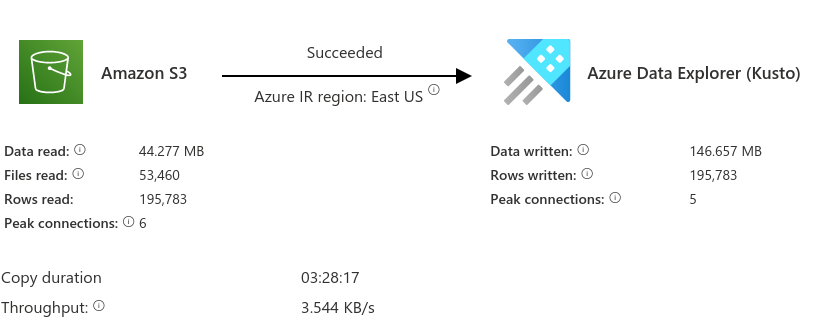
I really couldn’t believe that after working on building this out for a couple of weeks that the pipeline succeeded, and that the data was now available for me to query in Data Explorer using KQL.
For example, if I wanted to see the latest ten records sorted by timestamp of non-bots (at least from their user agent strings) of request to html content, I could make the following query:
tablename
| extend timestamp = todatetime(strcat(['date'], 'T', ['time']))
| where ['client-useragent'] !contains 'bot'
| where ['request-uri'] contains 'html'
| sort by timestamp desc
| limit 10
| project timestamp, ['edge-location'],['request-uri']The result from the query is presented to me in 73 ms.
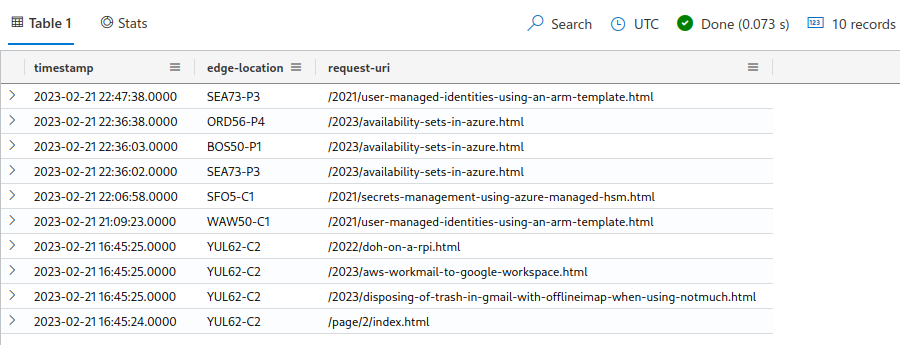
The best part about this solution is that it doesn’t require any additional JavaScript to be imported into the client’s browser. The data logged is from the HTTP requests sent to CloudFront which is providing the CDN ahead of the S3 bucket where this blog is being hosted.
If you made it this far, thank you! I really enjoyed putting this solution together. I learned a ton through the process about services in Azure that I never spent time with before. As I continue building queries and better reporting from the data, I’ll follow up with another post comparing the quality of the data to that which I typically see from Google Analytics.
Tweet to @kriation